TOC
作者 caiolombello 译者 梁远鹏
介绍和概述:
Kubernetes 已成为容器编排的事实标准,为管理大规模容器化应用程序提供了强大的平台。 Kubernetes 的一个基本功能是其自动缩放功能,它允许应用程序根据工作负载和性能指标进行扩展或缩减。在本文中,我们将探讨 Horizontal Pod Autoscaler(HPA),这是 Kubernetes 自动缩放的关键组件。我们将深入了解 HPA 的基础知识、工作原理以及如何使用自定义指标和资源限制来增强其性能。通过本文的学习,您将对HPA有一个扎实的理解,并知道如何配置它以优化您的 Kubernetes 部署。
Kubernetes中的自动缩放:
自动缩放是现代容器编排系统的一个关键功能,使应用程序能够根据需求和性能指标自动调整其资源。这种动态缩放允许系统保持最佳的性能和效率,同时最小化运营成本。
在Kubernetes中,自动缩放可以在不同的级别实现:
- 集群自动缩放:该组件通过根据资源利用率和需求添加或删除集群中的节点来扩展整个 Kubernetes 集群。
- Horizontal Pod Autoscaler(HPA):HPA根据预定义的性能指标(如CPU利用率、内存使用情况或自定义指标)调整特定部署或有状态集的副本数量。
- Vertical Pod Autoscaler(VPA):VPA 根据历史使用模式和当前资源需求自动调整 Pod 中各个容器的CPU和内存请求和限制。
自动缩放的重要性:
自动缩放提供了许多维护高效和弹性系统的优势,包括:
资源优化:自动缩放确保您的应用程序使用正确的资源量来满足其性能要求,减少了过度提供或欠提供的风险。 成本效益:通过根据工作负载自动调整资源,您可以最小化基础设施成本,因为您只支付实际需要的资源。 提高可靠性:自动缩放通过在高需求时进行扩展和在需求减少时进行缩减,以维护应用程序的可用性和性能,从而防止潜在的瓶颈或系统故障。 提高用户体验:通过确保您的应用程序具有处理不同工作负载所需的必要资源,自动缩放可以通过减少延迟和保持一致的性能来提高整体用户体验。
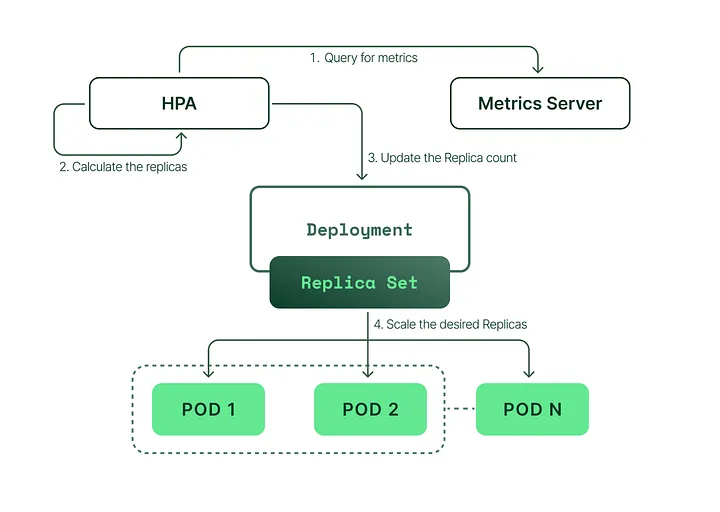
Kubernetes中的水平Pod自动缩放器(HPA)
Kubernetes 中水平 Pod 自动缩放器(HPA)的基本工作机制包括监控、缩放策略和 Kubernetes 度量服务器。让我们分解每个组件:
监控
HPA 持续监视 Kubernetes 集群中部署的Pod的指标。默认情况下,HPA 监视 CPU 利用率,但也可以配置为监视内存使用情况、自定义指标或其他每个 Pod 的指标。
对于每个 Pod 的资源指标(例如CPU),HPA 从每个目标Pod的资源指标 API 获取指标。基于目标利用率或原始值,控制器从所有目标 Pod 的这些值的平均值计算缩放比率。如果某些容器缺少相关资源请求,则 CPU 利用率将未被定义,该指标不会发生自动缩放。
对于每个 Pod 的自定义指标,控制器的操作方式类似,但使用原始值而不是利用率值。
对于对象和外部指标,HPA获取描述对象的单个指标,将其与目标值进行比较,并生成缩放比率。在自动缩放/v2 API版本中,在比较之前可以将该值除以 Pod 数。
这些指标由 Kubernetes Metrics 服务器收集和报告,它从每个节点上运行的 kubelet 汇总资源使用数据。
缩放策略:
在配置 HPA 时,您需要定义缩放策略来确定自动缩放器如何响应指标的变化。这些策略包括:
目标指标值: 这是您希望 HPA 维护的指标的期望值。例如,您可能会设置50%的目标 CPU 利用率,以确保您的 Pod 既不会过度负担也不会被浪费。 最小和最大副本数: 这些值定义了 HPA 可以将您的部署缩放到的最小和最大副本数。这可以防止过度缩放,从而可能导致负载过重或消耗过多的资源。
缩放决策:
HPA 使用收集的指标和定义的缩放策略来做出缩放决策。如果监视的指标超过目标值,HPA 将增加部署或状态集的副本数以更均匀地分配负载。相反,如果指标低于目标值,HPA 将减少副本数以节省资源。
Kubernetes Metrics Server:
Kubernetes Metrics Server 是资源使用数据的集群聚合器。它从每个节点上的 kubelet 收集数据,并向需要资源使用信息的 HPA 和其他组件提供指标。Metrics Server 是启用 Kubernetes 中实时指标和其他依赖于指标的功能的关键组件。
总之,在 Kubernetes 中,Horizontal Pod Autoscaler通过持续监视Pod指标,应用基于目标值和副本限制的缩放策略,做出缩放决策以维持最佳资源利用率。 Kubernetes Metrics Server 在为 HPA 提供必要数据以做出明智的决策方面发挥着关键作用。
HPA中的自定义指标
自定义指标是用户定义的性能指标,它们扩展了 Kubernetes 中水平 Pod 自动缩放器 (HPA) 支持的默认资源指标(例如 CPU 和内存)。默认情况下,HPA 基于 Pod 资源请求进行缩放决策,这代表 Pod 运行所需的最低资源。然而,这种方法可能不利于实现最佳性能。相反,基于资源限制进行缩放通常更有益,因为这可以确保应用程序不会达到其最大资源限制。自定义指标可以实现更精细和应用程序特定的自动缩放决策,从而提高资源利用率和系统性能。
为什么需要自定义指标:
虽然 Kubernetes 提供的默认指标,例如基于资源请求的 CPU 和内存使用情况,在许多情况下非常有用,但它们可能不足以满足所有应用程序的需求。基于资源限制进行缩放可以确保应用程序可以处理各种工作负载,而不会达到其允许的最大资源。自定义指标允许您根据应用程序的特定需求定制 HPA 的缩放行为,从而实现更精确和高效的自动缩放。
在HPA中使用自定义指标:
要在 HPA 中使用自定义指标,您需要:
确保您的集群设置支持自定义指标。这通常涉及部署自定义指标 API 服务器并配置必要的监视工具,如 Prometheus。
如果需要,在您的应用程序代码中定义自定义指标,并通过适当的端点公开它们。
通过在 HPA 清单中指定自定义指标来配置 HPA 使用它们。
自定义指标及其用例的示例:
请求速率
对于那些入站请求数量对资源消耗有显著影响的应用程序,您可以基于请求速率定义自定义指标。这使得 HPA 可以根据实际工作负载而不仅仅是 CPU 或内存使用情况来缩放副本数量。
用例:需要处理不同入站流量级别的 API 网关。
队列长度
对于从队列中处理任务的应用程序,您可以创建基于队列长度的自定义指标。这使得 HPA 可以根据任务积压量来缩放应用程序,以确保处理能力与工作负载相匹配。
用例:消费来自消息队列的后台作业处理服务。
应用特定的度量指标
您可能拥有特定于应用程序的独特性能指标,例如活动用户会话数量或数据库事务率。基于这些指标创建自定义度量指标可以帮助 HPA 更好地做出针对您应用程序行为的自适应扩展决策。 应用场景:一个电子商务平台在用户活动出现波动时需要相应地扩展其服务。
总之,HPA 中的自定义度量指标通过扩展 Kubernetes 支持的默认资源度量指标,实现了更加精确和特定于应用程序的自动扩展。通过利用自定义度量指标,您可以针对更广泛的应用程序和使用情况优化资源利用和性能。
配置具有 CPU 和内存限制的 HPA
为应用程序设置 CPU 和内存限制具有以下几个重要原因:
- 资源管理:通过指定资源限制,您可以防止单个 pod 或容器消耗过多的资源,这可能会影响运行在同一集群上的其他工作负载。
- 可预测的性能:设置限制确保您的应用程序在不同的工作负载下拥有足够的资源以实现最佳性能,最大程度地减少性能降低的可能性。
- 成本优化:通过限制资源使用,您可以避免在云资源或本地硬件上产生不必要的开支。
- 高效的自动缩放:正确配置的资源限制使水平 Pod 自动缩放器 (HPA) 能够做出更好的扩展决策,确保您的应用程序根据实际资源需求进行缩放。
使用自定义度量和资源限制配置 HPA 的逐步指南:
- 设置 Prometheus。我建议使用 kube-prometheus-stack Helm Chart,它会部署 cAdvisor 和其他必要的组件。
- 在 Prometheus 中创建自定义度量,以根据资源限制监视 CPU 和内存使用情况。将以下示例添加到 Prometheus 配置中:
CPU 使用限制自定义度量示例:
- record: pod:cpu_usage_percentage:ratio
expr: |
sum by (pod, namespace) (
node_namespace_pod_container:container_cpu_usage_seconds_total:sum_irate{cluster="",namespace!="",pod!=""}
)
/
sum by (pod, namespace) (
kube_pod_container_resource_limits{cluster="",job="kube-state-metrics",namespace!="",pod!="",resource="cpu"}
) * 100
内存使用限制自定义指标示例:
- record: pod:memory_usage_percentage:ratio
expr: |
sum by (pod, namespace) (
container_memory_working_set_bytes{cluster="",container!="",image!="",job="kubelet",metrics_path="/metrics/cadvisor",namespace!="",pod!=""}
)
/
sum by (pod, namespace) (
kube_pod_container_resource_limits{cluster="",job="kube-state-metrics",namespace!="",pod!="",resource="memory"}
) * 100
配置将替换默认的 Kubernetes Metrics-Server 的 Prometheus Adapter Chart。按照以下步骤操作:
配置 Prometheus Adapter 以使用 Prometheus 指标:
将自定义指标添加到 Prometheus 适配器(这些指标将在 Prometheus 中找到):
rules:
default: true
custom:
- seriesQuery: 'pod:memory_usage_percentage:ratio{namespace!="",pod!=""}'
resources:
overrides:
namespace: {resource: "namespace"}
pod: {resource: "pod"}
metricsQuery: '<<.Series>>{<<.LabelMatchers>>} / 100'
- seriesQuery: 'pod:cpu_usage_percentage:ratio{namespace!="",pod!=""}'
resources:
overrides:
namespace: {resource: "namespace"}
pod: {resource: "pod"}
metricsQuery: '<<.Series>>{<<.LabelMatchers>>} / 100'
您可以在官方文档中找到有关 Prometheus Adapter 规则的更多信息。
- 对于资源指标,您可以自定义查询以收集 CPU 和内存:
resource:
cpu:
containerQuery: |
sum by (<<.GroupBy>>) (
rate(container_cpu_usage_seconds_total{container!="",<<.LabelMatchers>>}[3m])
)
nodeQuery: |
sum by (<<.GroupBy>>) (
rate(node_cpu_seconds_total{mode!="idle",mode!="iowait",mode!="steal",<<.LabelMatchers>>}[3m])
)
resources:
overrides:
node:
resource: node
namespace:
resource: namespace
pod:
resource: pod
containerLabel: container
memory:
containerQuery: |
sum by (<<.GroupBy>>) (
avg_over_time(container_memory_working_set_bytes{container!="",<<.LabelMatchers>>}[3m])
)
nodeQuery: |
sum by (<<.GroupBy>>) (
avg_over_time(node_memory_MemTotal_bytes{<<.LabelMatchers>>}[3m])
-
avg_over_time(node_memory_MemAvailable_bytes{<<.LabelMatchers>>}[3m])
)
resources:
overrides:
node:
resource: node
namespace:
resource: namespace
pod:
resource: pod
containerLabel: container
window: 3m
- 部署 Prometheus Adapter
helm repo add --force-update prometheus-community https://prometheus-community.github.io/helm-charts
helm upgrade --install -n monitoring \
prometheus-adapter prometheus-community/prometheus-adapter --version 4.1.1 -f metrics-server.yaml
- 检查自定义指标是否成功应用
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/" | jq
- 为演示,请使用定义了资源限制和请求的 NGINX 进行部署:
helm repo add --force-update bitnami https://charts.bitnami.com/bitnami
helm upgrade --install \
--set resources.limits.cpu=100m \
--set resources.limits.memory=128Mi \
--set resources.requests.cpu=50m \
--set resources.requests.memory=64Mi \
nginx bitnami/nginx --version 13.2.29
- 部署使用了自定义metrics的HPA
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: nginx-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: nginx
minReplicas: 1
maxReplicas: 10
metrics:
- type: Pods
pods:
metric:
name: pod:memory_usage_percentage:ratio
target:
type: Utilization
averageValue: 0.8 # 80%
- type: Pods
pods:
metric:
name: pod:cpu_usage_percentage:ratio
target:
type: Utilization
averageValue: 0.8 # 80%
kubectl apply -f demo/nginx-hpa.yaml
如果是使用 helm chart,那么这么 yaml 文件对应的模板是这样的:
templates/hpa.yaml
{{- if .Values.autoscaling.enabled }}
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: {{ include "app.fullname" . }}
labels:
{{- include "app.labels" . | nindent 4 }}
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: {{ include "app.fullname" . }}
minReplicas: {{ .Values.autoscaling.minReplicas }}
maxReplicas: {{ .Values.autoscaling.maxReplicas }}
metrics:
{{- if .Values.autoscaling.targetCPUUtilizationPercentage }}
- type: Pods
pods:
metric:
name: pod:cpu_usage_percentage:ratio
averageValue: {{- div .Values.autoscaling.targetCPUUtilizationPercentage 100 -}}
{{- end }}
{{- if .Values.autoscaling.targetMemoryUtilizationPercentage }}
- type: Pods
pods:
metric:
name: pod:memory_usage_percentage:ratio
averageValue: {{- div .Values.autoscaling.targetMemoryUtilizationPercentage 100 -}}
{{- end }}
{{- end }}
values.yaml
autoscaling:
enabled: true
minReplicas: 1
maxReplicas: 2
targetCPUUtilizationPercentage: 80
targetMemoryUtilizationPercentage: 80
- 检查 HPA 是否正常工作
kubectl get hpa nginx-hpa
结论
在本文中,我们探讨了 Kubernetes 水平 Pod 自动缩放器(HPA)在有效管理应用程序资源和可伸缩性方面的重要性。我们讨论了默认 HPA 的局限性,它依赖于 Pod 资源请求,以及使用基于资源限制的自定义指标以获得更好性能的好处。
通过设置 Prometheus 和 Prometheus Adapter,我们演示了如何创建 CPU 和内存使用情况的自定义指标,并配置 HPA 使用这些指标进行更精确的自动缩放。按照逐步指南,您可以实施这些概念和技术,以优化应用程序的资源使用,并提高其整体性能。
我鼓励您将这些原则和技术应用到您的 Kubernetes 部署中,并体验基于自定义指标的高效和弹性自动缩放的优势。祝您愉快地进行缩放!
原文地址
微信公众号
扫描下面的二维码关注我们的微信公众号,第一时间查看最新内容。同时也可以关注我的Github,看看我都在了解什么技术,在页面底部可以找到我的Github。