TOC
前言
上一篇,我们介绍了 SOFARPC 同步异步的实现,本文我们将会介绍 SOFARPC 中的线程模型。
本文会从同步异步,阻塞非阻塞开始讲起,进而探讨常见的线程模型设计,之后,我们会介绍下 SOFABolt 中对 Netty 的模型使用,最后 SOFARPC 在一次调用过程中各个步骤执行的线程。
几种常见的 IO 模型
首先介绍一下 Linux 的几种 IO 模型,以进程从 Socket 中读取数据为例。实际上,进程最终是通过 recvfrom 系统调用来读取数据。这个时候,系统内核在收到之后,根据 IO 模型的不同,处理是不同的。
注意,图下的红色部分表示阻塞时间。
阻塞 I/O

阻塞 I/O(blocking I/O) 模型是最流行,最简单易用的 I/O 模型,默认情况下,所有套接字和文件描述符就是阻塞的。阻塞 I/O 将使请求进程阻塞,直到请求完成或出错。
非阻塞 I/O

非阻塞 I/O(nonblocking I/O)的含义:如果 I/O 操作会导致请求进程休眠,则不要把它挂起,也就是不会让出 CPU,而是返回一个错误告诉它(可能是 EWOULDBLOCK 或者 EAGAIN)。
I/O 复用

I/O 多路复用(I/O multiplexing)会用到 select 或者 poll 或者 epoll 函数,这几个函数也会使进程阻塞,但是和阻塞 I/O 所不同的的,函数可以同时阻塞多个 I/O 操作。而且可以同时对多个读操作,多个写操作的 I/O 函数进行检测,直到有数据可读或可写时,才真正调用 I/O 操作函数。
信号驱动式 I/O

信号驱动 I/O(signal-driver I/O)使用信号,让内核在描述符就绪时发送 SIGIO 信号通知我们进行处理,这时候我们就可以开始真正的读了。
异步 I/O

异步 I/O(asynchronous I/O)由 POSIX 规范定义,包含一系列以 aio 开头的接口。一般地说,这些函数的工作机制是:告知内核启动某个操作,并让内核在整个操作(包括将数据从内核空间拷贝到用户空间)完成后通知我们。
这种模型与信号驱动模型的主要区别是:信号驱动 I/O 是由内核通知我们何时可以启动一个 I/O 操作,而异步 I/O 模型是由内核通知我们 I/O 操作何时完成。
汇总
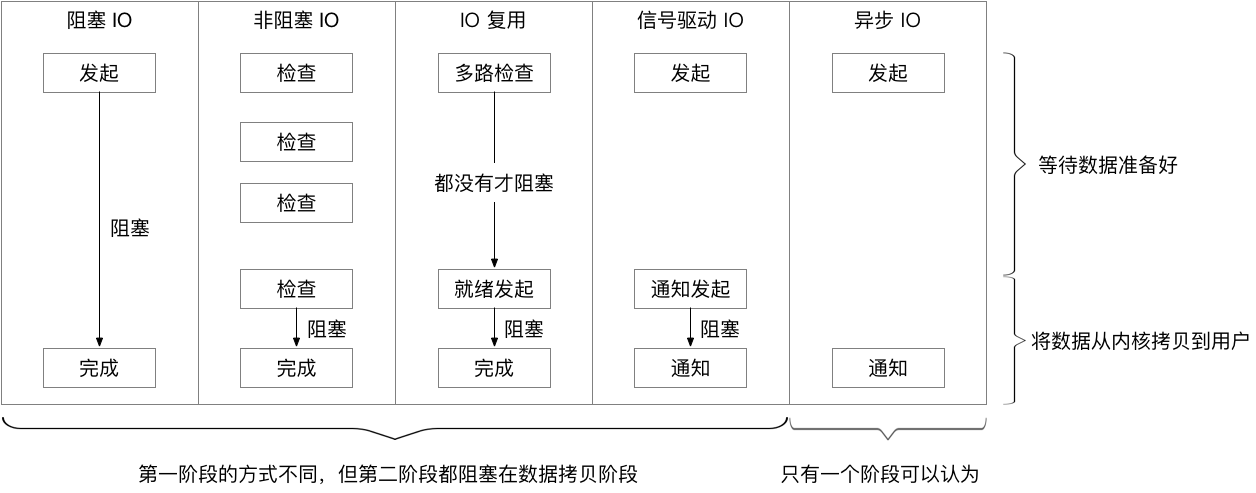
综上,我们给出一个大家比较熟知的比较图。方便理解。
JAVA BIO & NIO
在了解了内核层面上这几个线程模型之后,我们要给大家介绍下 JAVA BIO 和 JAVA NIO。
JAVA BIO
首先我们给大家看一个直接使用 JAVA BIO 写得一个服务端。
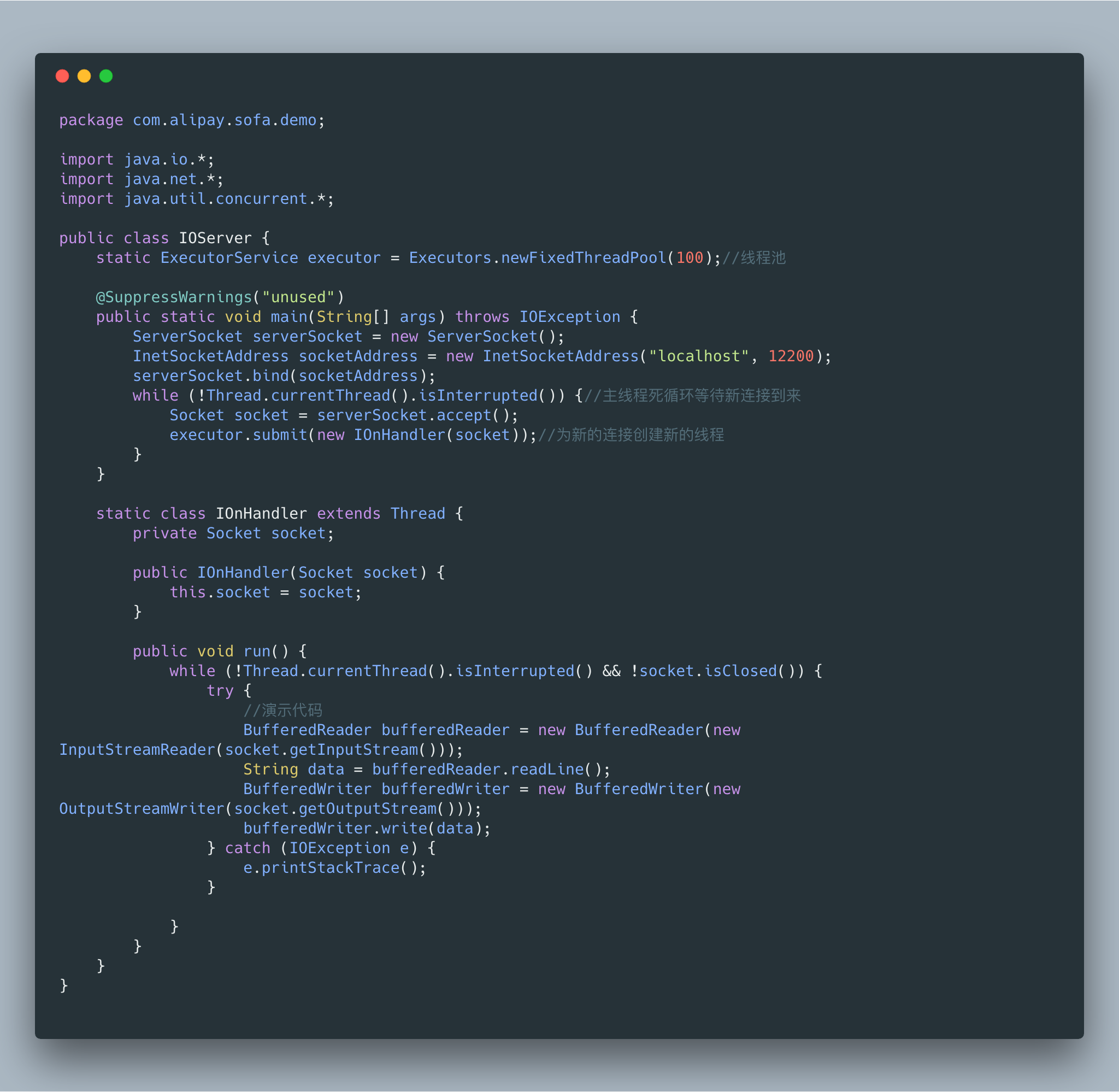
传统的BIO里面socket.read(),如果TCP RecvBuffer里没有数据,调用会一直阻塞,直到收到数据,返回读到的数据。
JAVA NIO
对于NIO,如果TCP 的buffer中有数据,就把数据从网卡读到内存,并且返回给用户;反之则直接返回0,永远不会阻塞。下面是一段比较典型的 NIO的处理代码。
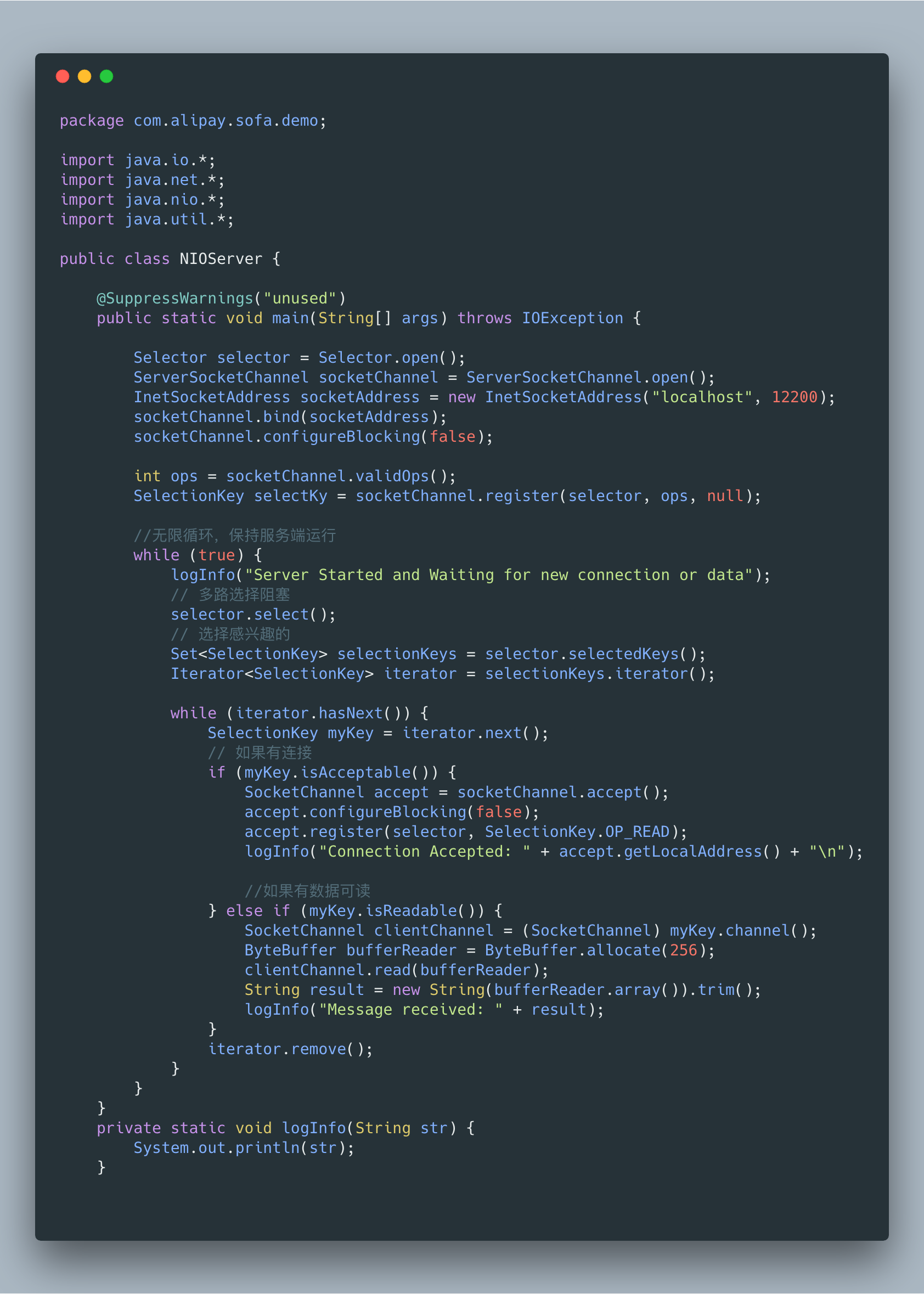
在我们可以将 JAVA NIO和多路复用结合起来。这里也是最简单的Reactor模式:注册所有感兴趣的事件处理器,单线程轮询选择就绪事件,执行事件处理器。
这里简单比较了一下以前的 BIO和现在的 NIO,新的 NIO 给我们带来了如下的好处。
- 事件驱动模型
- 单线程处理多任务
- 非阻塞I/O,I/O读写不再阻塞,而是返回0
- 基于快的传输,比基于流的传输更高效
- 更高级的IO函数,零拷贝
- 允许IO多路复用
Reactor 线程模型
前面说了,我们有了 JAVA NIO ,可以用多路复用。有些同学可能会问,不能直接使用吗?答案是可以直接使用,
但是技术层面上的问题虽然解决了,在工程层面,实现一个高效没有问题的架构依然很难,而且这种多路复用,对编程思维有比较大的挑战,所以,工程层面还不够。因此,有了 Reactor 编程模型
一般情况下,I/O 复用机制需要事件分发器,以上这个分发事件的模型太简单了。实际使用起来会有一些性能问题。目前比较流行的是 Reactor 和 Proactor,本文不介绍 Proactor 模型,有兴趣的同学可以自己学习。
标准/典型的 Reactor 中定义了三个角色:

而一个标准的操作流程则是
- 步骤1:等待事件到来(Reactor 负责)。
- 步骤2:将读就绪事件分发给用户定义的处理器(Reactor 负责)。
- 步骤3:读数据(用户处理器负责)。
- 步骤4:处理数据(用户处理器负责)。
在这个标准之下,Reactor有几种演进模式可以选择。注意 Reactor 重点描述的是 IO部分的操作,包括两部分,连接建立和 IO读写。
单线程模型
Reactor 单线程模型指的是所有的IO操作都在同一个NIO线程上面完成,NIO线程的职责如下:
1. 作为 NIO 服务端,接收客户端的 TCP 连接;
2. 作为 NIO 客户端,向服务端发起 TCP 连接;
3. 读取通信对端的请求或者应答消息;
4. 向通信对端发送消息请求或者应答消息。

这是最基本的单 Reactor 单线程模型。其中 Reactor 线程,负责多路分离套接字,有新连接到来触发 connect 事件之后,交由 Acceptor 进行处理,有 IO 读写事件之后交给 hanlder 处理。
Acceptor 主要任务就是构建 handler ,在获取到和 client 相关的 SocketChannel 之后 ,绑定到相应的 handler上,对应的 SocketChannel 有读写事件之后,基于 reactor 分发,hanlder 就可以处理了(所有的 IO 事件都绑定到selector 上,由 Reactor 分发)。
该模型 适用于处理器链中业务处理组件能快速完成的场景。不过,这种单线程模型不能充分利用多核资源,所以实际使用的不多。
多线程模型
Reactor 多线程模型与单线程模型最大的区别就是将 IO 操作和非 IO 操作做了分离。效率提高。

Reactor多线程模型的特点:
1. 有专门一个NIO线程-Acceptor 线程用于监听服务端,主要接收客户端的 TCP 连接请求;
2. 网络 IO 操作-读、写等由一个单独的 NIO 线程池负责,线程池可以采用标准的 JDK 线程池实现,它包含一个任务队列和 N 个可用的线程,由这些 NIO 线程负责消息的解码、处理和编码;
主从多线程模型
这个也是目前大部分 RPC 框架,或者服务端处理的主要选择。
Reactor 主从多线程模型的特点:
服务端用于接收客户端连接的不再是个1个单独的 NIO 线程,而是一个独立的 NIO 线程池。

主要的工作流程
- MainReactor 将连接事件分发给 Acceptor
- Acceptor 接收到客户端 TCP 连接请求处理完成后(可能包含接入认证,黑名单等),将新创建的 SocketChannel 注册到 IO 线程池(sub reactor线程池)的某个IO线程上,Acceptor 线程池仅仅只用于客户端的登陆、握手和安全认证。
- SubReactor 负责 SocketChannel 的读写和编解码工作。其 IO 线程负责后续的 IO 操作。
SOFARPC 线程模型
整体线程模型
对于 SOFARPC 来说,和底层的 SOFABolt 一起,在使用 Netty 的 Reactor 主从模型的基础上,支持业务线程池的选择。
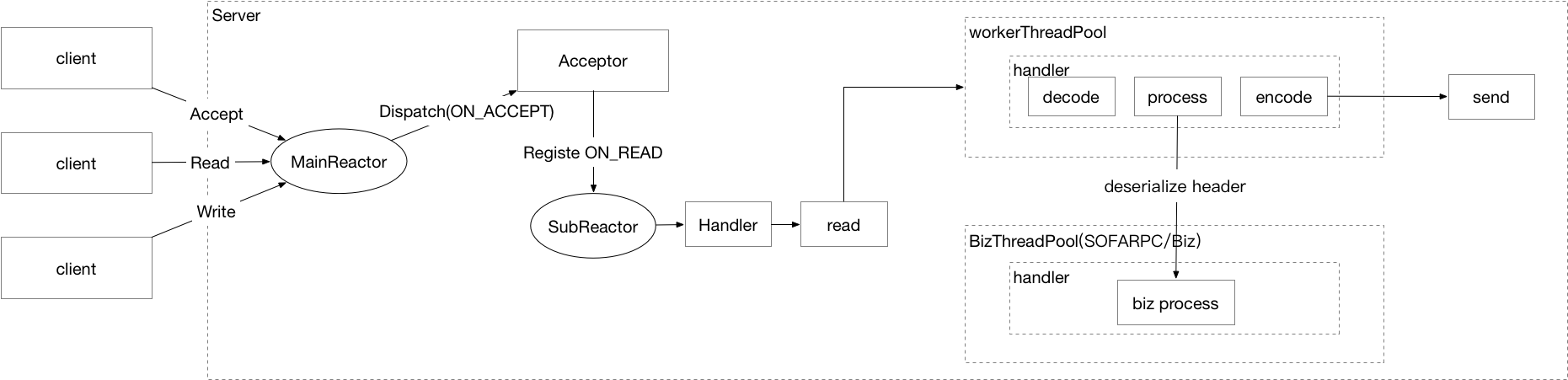
线程模型
目前 SOFARPC 服务端的线程模型在综合考虑,和一些历史压测的数据支撑的情况下,我们选了主从线程模型,并对序列化和业务代码执行使用一个 BizThreadPool(允许对线程池的核心线程数,队列等进行调整),或者自定义的线程池。将序列化,反序列化等。这些耗时的操作,全部放在了Biz线程池中,这样,可以有效地提高系统的整体吞吐量。
特别的,这里对于 header部分,我们将反序列化放在了 Worker线程中,这样,可以在对性能影响极低的情况下,可以提供一些额外的好处,比如允许业务配置接口对应的线程池。
默认执行步骤
一次比较完整的 RPC 调用的时候,以下为默认的执行线程。
- 客户端 长连接:Netty-Worker 线程 序列化请求/反序列化响应:发起请求的线程,如果是 callback,是新的一个线程。 心跳:Netty-Worker 线程
- 服务端 端口:Netty-Boss 线程 长连接:Netty-Worker 线程 心跳:Netty-Worker 线程 反序列化请求Header:Netty-Worker 线程 反序列化请求Body/序列化响应:SOFARPC 业务线程池
自定义业务线程池
SOFARPC 支持自定义业务线程池,可以为指定服务设置一个独立的业务线程池,和 SOFARPC 自身的业务线程池是隔离的。多个服务可以共用一个独立的线程池。
实现原理
自定义线程池管理器封装服务接口和自定义线程池映射关系,用户创建配置自定义线程池,提供指定服务注册自定义线程池。
BOLT 支持部分反序列化,所以框架会在 IO 线程池提前反序列化请求的 Header 头部数据,注意,这部分一个普通的 Map,操作很快,一般不会成为瓶颈,Body 数据还是在业务线程内反序列化。
核心代码在自定义线程池管理器里:
com.alipay.remoting.rpc.protocol.RpcRequestProcessor#process 选择线程池
UserThreadPoolManager 注册线程池。
感兴趣的同学可以去看下。
使用方式
请求处理过程,默认是一个线程池,当这个线程池出现问题则会造成整体的吞吐量降低。而有些业务场景,希望对核心的请求处理过程单独分配一个线程池。SOFARPC 提供线程池选择器设置到用户请求处理器里面,调用过程即可根据选择器的逻辑来选择对应的线程池避免不同请求互相影响。
通过sofa:global-attrs元素的 thread-pool-ref 属性为该服务设置自定义线程池。
<bean id="customExcutor" class="com.alipay.sofa.rpc.server.UserThreadPool" init-method="init">
<property name="corePoolSize" value="10" />
<property name="maximumPoolSize" value="10" />
<property name="queueSize" value="0" />
</bean>
<sofa:service ref="helloService" interface=" com.alipay.sofa.rpc.service.HelloService">
<sofa:binding.bolt>
<sofa:global-attrs thread-pool-ref="customExcutor"/>
</sofa:binding.bolt>
</sofa:service>
总结
通过这篇文章,我们介绍了几种常见的 IO 模型,介绍了 JAVA 中的 IO和 NIO,同时也介绍了 IO 模型在工程上实践不错的 Reactor 模型。
最后,介绍了 SOFARPC 的线程模型,希望大家对整个线程模型有一定的理解,如果对 SOFARPC 线程模型和自定义线程池有疑问的,也欢迎留言与我们讨论。
文章转自剖析 | SOFARPC 框架】之SOFARPC 线程模型剖析
注意: 由于原文章链接发生变更,因此将链接更新为 sofastack 官网,可在官网查询相关文章.
微信公众号
扫描下面的二维码关注我们的微信公众号,第一时间查看最新内容。同时也可以关注我的Github,看看我都在了解什么技术,在页面底部可以找到我的Github。